浏览器请求一个网页的流程
一切从URI 说起
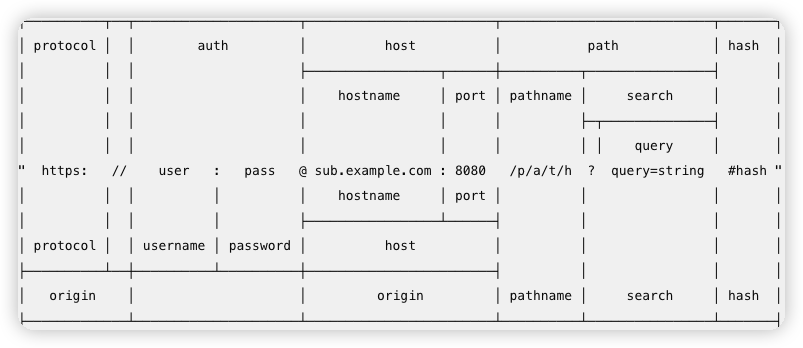
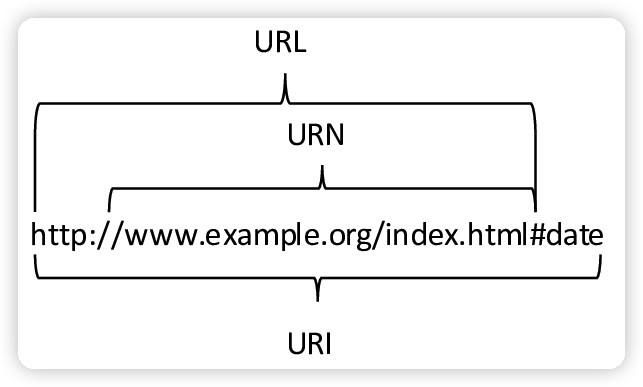
- URI: Uniform Resource Indentifier 统一资源标识符 ->
protocol+auth+host+path+hash - URL: Uniform Resource Locator 统一资源定位符 ->
protocol+auth+host+path - URN: Uniform Resource Name 统一资源命名 ->
host+path - URI 包括 URL 和 URN
客户端 & 服务端
客户端: 获取信息/服务的电脑 服务端: 提供信息/服务的电脑
cs架构: client/server
将应用程序安装在客户端电脑中, 服务端只负责提供客户端需要的数据 优点: 安全性好, 响应速度快,UI自定义程度高,功能操作丰富 缺点: 需要安装指定的软件应用程序或者硬件,需要手动更新迭代版本,维护成本高 例如: PC端的, QQ, 微信, 网易云音乐
bs架构: browser/server
利用web浏览器呈现客户端界面, 服务端只负责提供客户端需要的数据 优点: 无需安装特定的软件或硬件, 跨平台, 交互性强, 无需手动安装/升级客户端 缺点: 功能操作和安全性相对较弱, 需要兼容各种不同浏览器内核 例如: 网页端的, QQ音乐, 网易云音乐
服务器 & 域名 & 通信协议 & http协议
服务器
通俗理解就是提供信息/服务的电脑
域名
通俗的理解就是: 服务器的家庭住址(IP地址)别名
什么是通信协议?
通俗的理解就是: 电脑和电脑之间说话(数据交互)用的语言, 比如中国人用汉语交流, 汉语就可以理解为是人的一种通信协议 除了汉语,世界上还有其他的国家的人用其他的语言交流, 比如英国人用的英语
常见的通信协议:
- http, 应用最广泛的通信协议
- ftp
- ssh
- ....
HTTP 协议
MDN 参考文档: https://developer.mozilla.org/zh-CN/docs/Web/HTTP
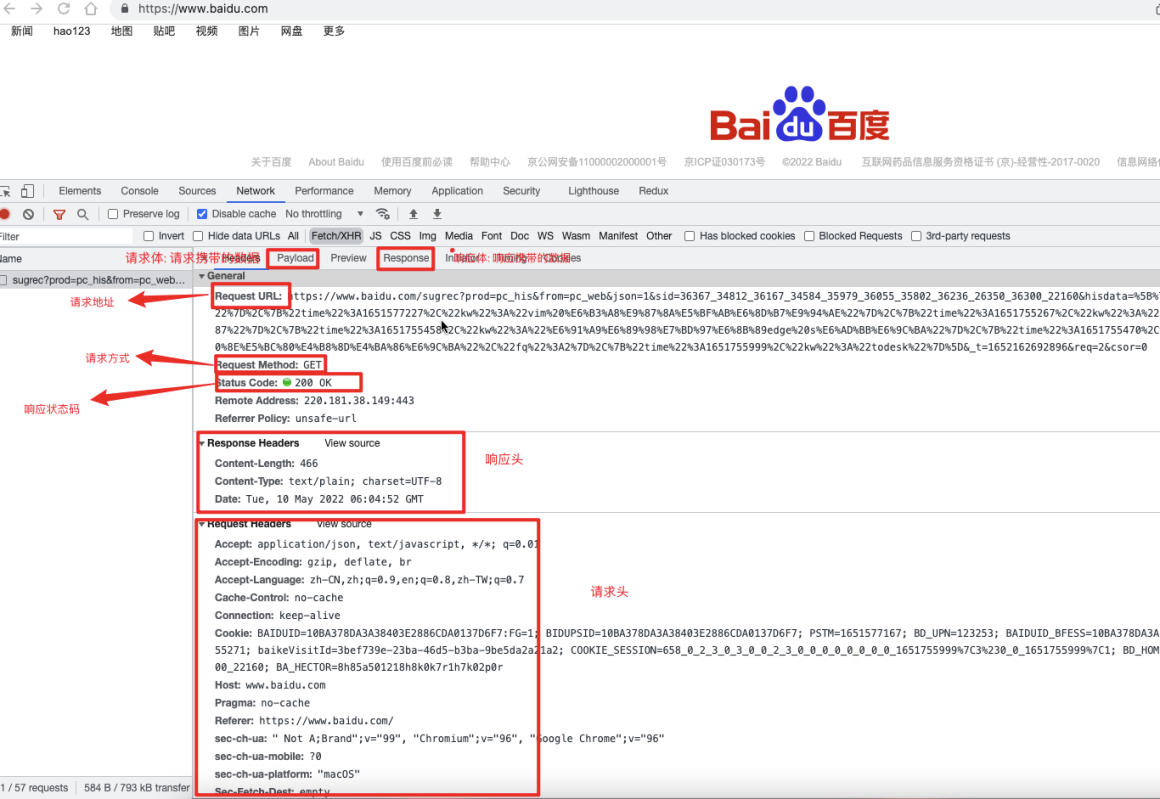
请求和响应 Request & Response
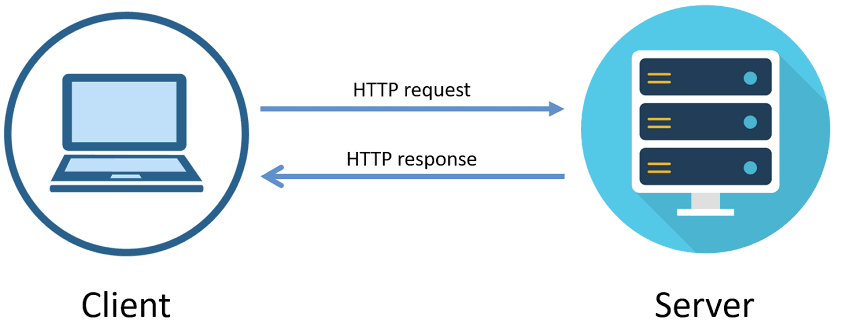
请求/响应 & 报文格式
请求:
- 请求头: (请求方法/请求url/http版本/携带数据的格式/自定义字段)
- 请求体: (携带的数据)
- 常见请求头:
| 字段 | 示例 | 取值范围 | 意义 |
|---|---|---|---|
| Accept | application/json; charset=UTF8; | mime-type 对照表 | 告诉服务端, 客户端希望接收到的数据格式 |
| Accept-Langue | zh-CN,zh,en-US | zh-Cn: 简体中文 zh: 中文 en-US: 英文 | 告诉服务端,客户端希望收到的文档的语言是zh-Cn(简体中文),如果是图片/或是其他,没有这个 header |
| Accept-encoding | gzip,defalt,br | gzip | 由于http传输数据时会压缩数据,这个就是告诉服务端, 用哪种压缩方式 |
响应:
- 响应头: (HTTP状态码/响应数据的格式/自定义字段)
- 响应体: (响应回来的数据)
- 常见响应头字段:
| 字段 | 示例 | 取值范围 | 意义 |
|---|---|---|---|
| Content-Type | application/json; charset=UTF8; | mime-type 对照表 | 告诉客户端响应的数据的格式 |
请求头/响应头的参考:: https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers
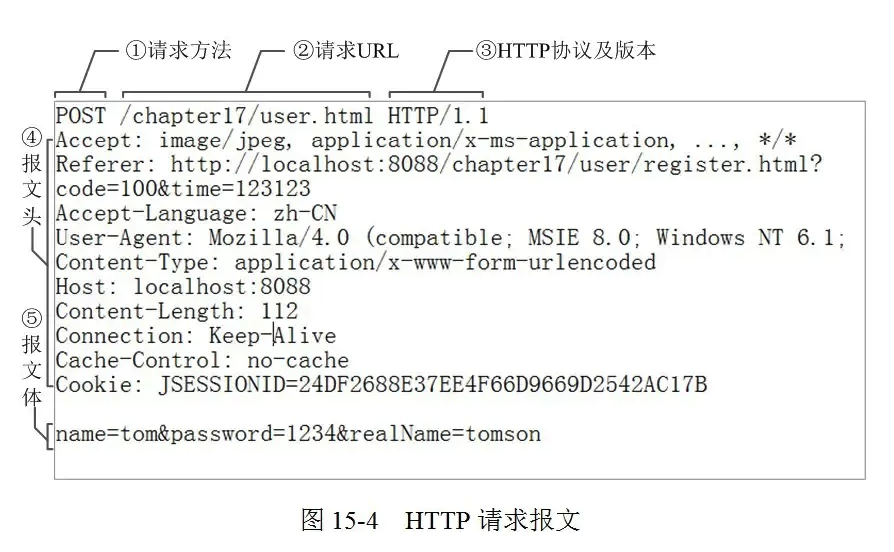
报文格式(请求&响应)
无论是请求数据包还是响应数据包都是这种格式
HTTP常见的状态码 Status Code
| 分类 | 描述 |
|---|---|
| 1xx | 信息,服务器收到请求,需要请求者继续执行操作 |
| 2xx | 成功, 请求被成功接收并处理 |
| 3xx | 重定向页面(301/302)/缓存(304) |
| 4xx | 客户端错误: 比如404, 请求的页面不存在 |
| 5xx | 服务器错误: 比如服务端代码语法错误 |
参考资料: https://www.runoob.com/http/http-status-codes.html
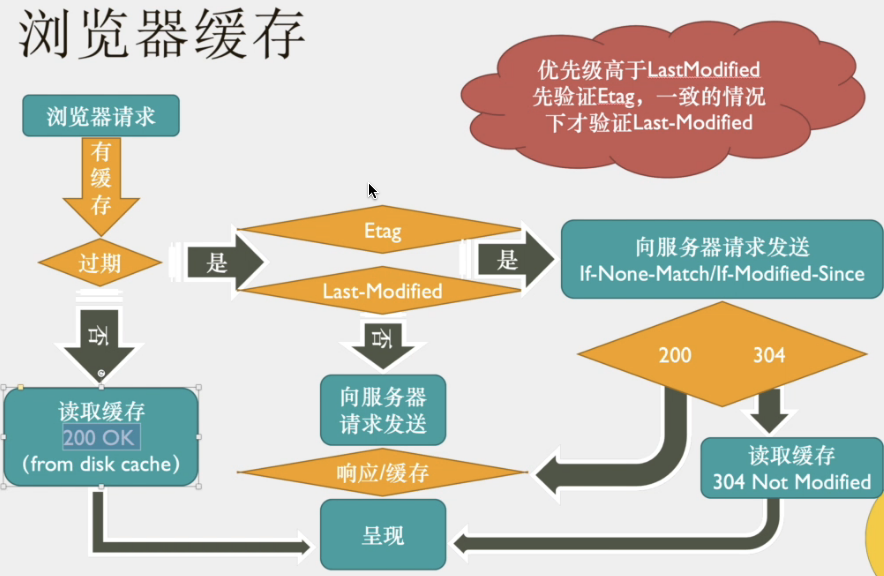
浏览器缓存
实践是检验真理的唯一标准: 测试浏览器缓存项目代码
使用缓存的好处
- 减少网络宽带的消耗
- 减少服务器压力
- 提升用户体验
开启浏览器缓存
- 使用http响应头来设置这些字段
- 关闭浏览器禁用缓存的功能
| 字段 | 取值范围 | 意义 |
|---|---|---|
| Pragma | no-cache | 告诉客户端不要使用浏览器缓存,每次都去服务端获取最新的数据 |
| Expires Cache-Control | no-cache no-store max-age=xxx public private | 缓存控制 HTTP1.1使用的字段,http协议是向下兼容的,所以这个字段在后面的版本中还是可以用的 |
注意: Expires 是 http1.0版本用的, 优先级比 cache-control 更低, 推荐使用 Cache-Control
- Cache-Control 字段取值及其意义
| 取值 | 意义 |
|---|---|
| no-cache | 告诉浏览器忽略缓存,每次都到服务器都获取最新的资源(依然会缓存) |
| no-store | 告诉浏览器不要缓存 |
| max-age=31536000 | 告诉浏览器缓存过期时间, 从请求开始时间到缓存过期这个时间段的秒数 |
| public | 表示这个响应可以被任何对象缓存(浏览器客户端, 代理服务器) |
| private | 表示响应只能被单个用户缓存, 不能作为共享缓存(浏览器客户端是可以的, 但是代理服务器不能) |
禁用浏览器缓存
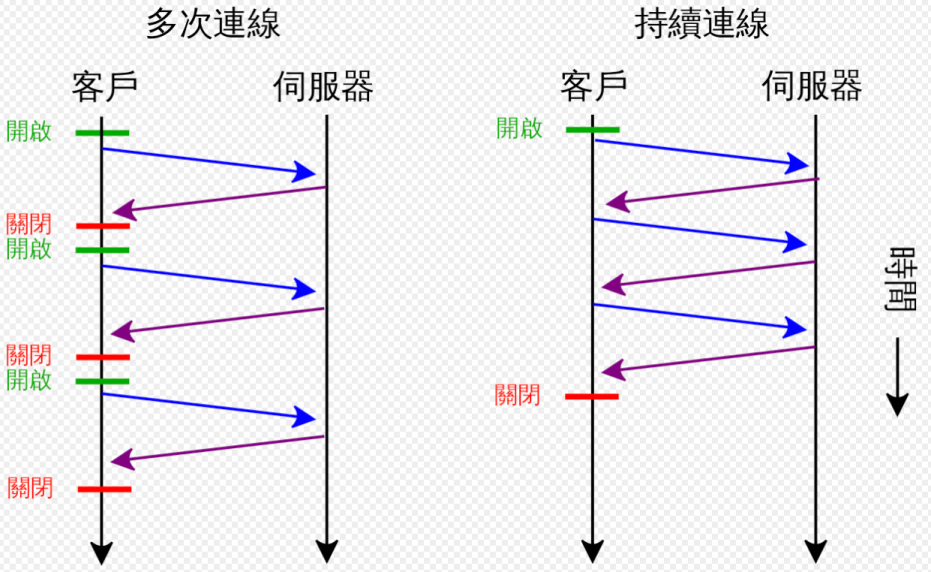
长连接 && 短连接
在请求头中加上(http1.1以后, 浏览器会自动加) connection:keep-alive, 当然, 必须服务端也支持这个长链接才行 短连接: 3次握手建立连接后, 获取完一个资源后就会立即断开,下一次获取资源的时候,再次重新链接 长连接: 3次握手建立连接后, 获取完一个资源后不会立即断开, 在指定时间后才会断开连接(根据浏览器和服务端使用的服务器软件不一样 比如nginx 和 apache 就不一样)
这种长连接只是浏览器和web server对获取资源的一种优化手段
referrer
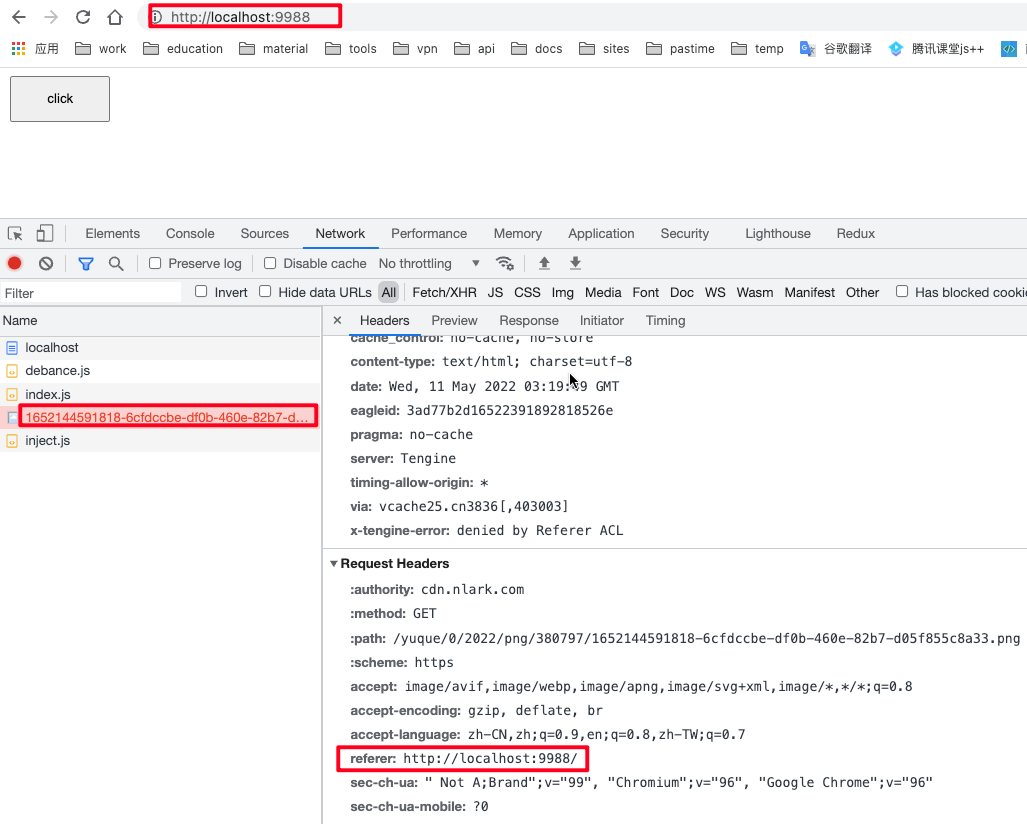
referer 本来是 应该是 referrer 的, 但是为了做兼容, 所以 referer也是可以生效的
在请求头中记录来源的字段, 就是说在google中搜索腾讯课堂, 然后从搜索结果的页面点击进入腾讯课堂, 此时来源就是 https://www.google.com 一般会用于通过分析不同渠道的流量分布用户搜索的关键字是从哪个链接进入的网站, 还可以做 防盗链接
referrer 用处
- 防盗链, 服务器在给到客户单资源之前,先判断是否是 referrer 自己的网站域名, 不是就拦截, 是就正确返回
- 分析不同渠道的流量分布,针对性的做宣传(比如一个网站大部分得流量都是从百度搜索进入的, 那就可以适当的进行百度的seo优化)
防止盗链测试(用yuque的图片)
比如以下这个代码, 我用 file协议直接打开是可以正常加载出来的, 但是: 如果我把这个html放到服务器上, 就无法加载出来了
<!doctype html>
<html lang="en">
<head>
<title>js</title>
</head>
<body>
<img
src="https://cdn.nlark.com/yuque/0/2022/png/380797/1652144591818-6cfdccbe-df0b-460e-82b7-d05f855c8a33.png"
alt="羽雀的图片"
/>
</body>
</html>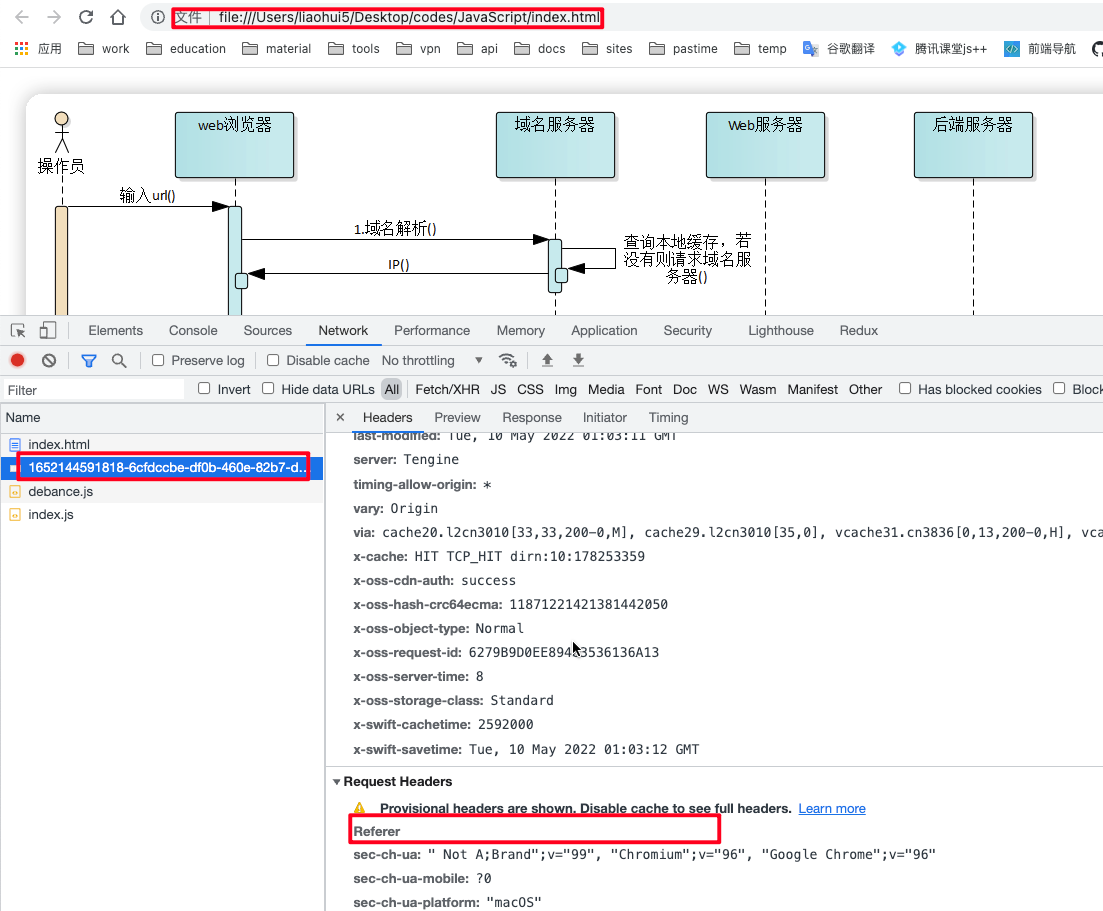
referer 设置方法
- no-referrer: 不在请求头中添加 referrer 字段
- origin: 源域名
- no-referrer-when-downgrade: 源URI(不设置默认就是这个值)
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>js</title>
<!--
content 的取值可以是:
1. no-referrer: 不设置 referrer
2. origin: 源域名
3. no-referrer-when-downgrade: 源URI(不设置默认就是这个值)
在协议降级(如使用https页面中引入了http协议资源)时不发送referrer信息, 是大部分浏览器的默认策略
-->
<meta name="referrer" content="no-referrer" />
</head>
<body>
<img
src="https://cdn.nlark.com/yuque/0/2022/png/380797/1652144591818-6cfdccbe-df0b-460e-82b7-d05f855c8a33.png"
alt=""
/>
</body>
</html>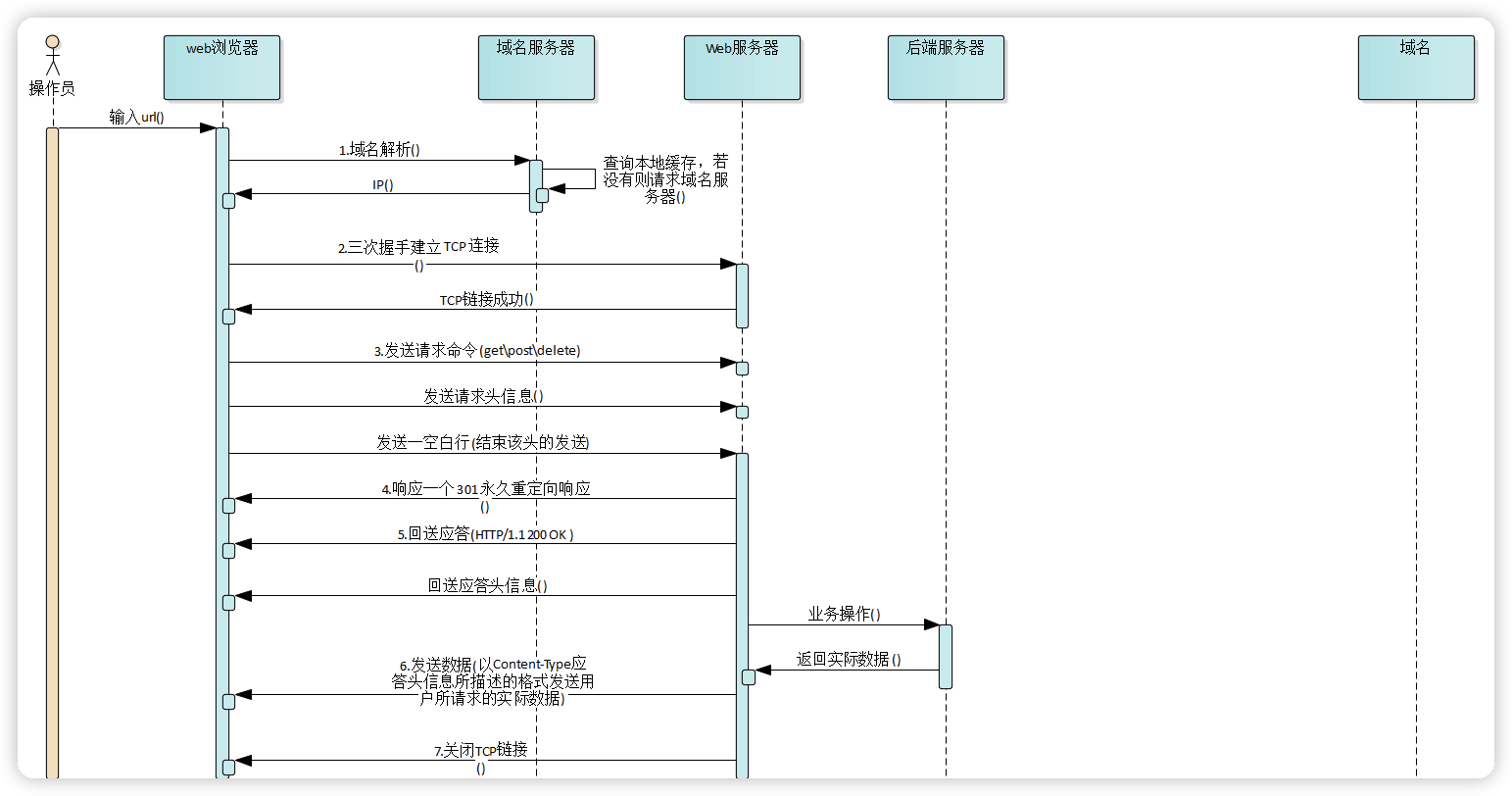
HTTP协议版本
HTTP 1.1版本
- 增加长链接: connection: keep-alive
- 支持多个请求同时发送
- 增加了
PUT/PATCH/DELETE/OPTION等请求方式 - 增加了
host字段 - 增加了
100状态码(Continue) 支持只发送头信息 - 增加身份认证机制( http://user:password@expample.com )
2.0版本
- 增加了双工模式(客户端可以同时发送多个请求, 服务端可以同时处理多个请求)
- 可以使用二进制就行传输
- 服务端推送
同源策略 Some-Origin-Policy
浏览器的同源策略
域名``端口``协议都相同的URL才是同源的URL
同源策略是浏览器的一个基础安全功能, 不同源的客户端在没有服务端授权的情况下, 不能读写对方资源,只有同一个源的脚本才能操作dom,读写cookie,session,ajax等操作的权限
浏览器不受同源策略的操作项
- 页面超链接/页面重定向
- 表单提交(比如从
www.example.com/form.html提交表单到www.qq.com/login.html) - 静态资源引入(
script-src/link-src/img-src/iframe-src)
如何跨域
最常用的方式有两种
- 代理: 同源策略是针对浏览器的, 所以先让浏览器请求代理服务器然后再请求到目标服务器就可以解决跨域问题
- 服务端设置允许跨域: 直接在响应头中设置对应字段, 告诉浏览器允许指定网站可以跨域正常访问
- 利用静态资源引入不受同源策略影响的操作性想办法(比如: jsonp), 参考
三次握手(建立连接)
四次挥手(关闭连接)
减少HTTP请求(优化)
- 使用雪碧图(精灵图)合并小图片/使用编码(base64)来存储小图片
- 合理的合并js脚本和css样式表(webpack/vite)
- 使用CDN来存储静态资源(比如: 视屏文件/软件二进制包等大文件)
- 使用浏览器缓存